목차
연산자 오버로딩의 이해
이제 C++에 대해서 어느 정도 감이 잡혔다.
이번에는 C++의 핵심적인 기능 중 하나인 연산자 오버로딩을 살펴보자.
지난 글까지 객체 다형성과 함수의 다형성에 대해서 들여다 봤다.
하지만 C++ 다형성의 끝판왕은 개인적으로 연산자 오버로딩이라 생각한다.
기본적인 원리와 방식은 기존과 동일하므로 어렵지 않게 공부할 수 있으니 한 번 들여다 보자.
연산자의 오버로딩은 함수의 오버로딩과 거의 차이가 없다.
return 타입을 제외한 키값들, 함수명과 인자의 타입, 개수만이 오버로딩의 조건이 된다.
즉 return 타입은 오버로딩과 관련이 없었다는 것을 기억하고 천천히 접근해보자.
가장 기본적인 이해를 위해 잠깐 생성자의 호출을 다시 돌아보자.
앞서 살펴본 생성자 중 복사 생성자라는게 있었다.
복사 생성자는 자기 자신과 같은 타입의 매개 변수로 객체를 초기화할 때 사용하던 생성자다.
내가 직접 설정해주지 않아도 컴파일러가 얕은 복사로 자동으로 작성해주던 녀석이다.
복사 생성자는 생성자와 똑같이 작동했었다.
다음의 코드가 어떻게 작동했는지 기억해보자.
#include <iostream>
using namespace std;
class Product {
int var;
public:
void print() { cout << var << "\n"; }
void set(int x) { var = x; }
};
int main() {
Product a;
a.set(10);
Product b(a);
Product c = a;
a.print();
b.print();
c.print();
}
Product a 를 선언하고 a.var을 10으로 설정해주었다.
Product b 는 a를 매개 변수로 받아 생성자를 호출하는 복사 생성자가 사용되어서 var=10의 얕은 복사가 되었다.
그렇다면 Product c 는 어떤가?
우리가 =을 사용하려는 Product 클래스는 =에 대한 정의를 일절 하지 않았다.
특히 이상함을 알아보려면 a+c 가 수행되는지 보면 되는데, 당연히 Product 에는 +에 대한 정의가 없기 때문에 컴파일이 되지 않는다.
=은 그럼 왜 되는가?
=은 컴파일러에 의해 다음과 같이 해석이 된다.
Product c= a; => Product c(a);
물론 정확하게 이렇게 변환되는 것은 아닐수도 있는데, 어쨌든 의미를 살펴보면, 결국 컴파일러는 =을 c(a)와 동일하게 취급하고, 그에 따라 복사 생성자가 호출되어 c가 초기화 된다.
이를 뒷받침하기 위해 다음 코드를 살펴보자.
#include <iostream>
using namespace std;
class Product {
int var;
public:
Product() {}
Product(Product& a) {
cout << "COPY CONSTRUCTOR CALLED\n";
}
void print() { cout << var << "\n"; }
void set(int x) { var = x; }
};
int main() {
Product a;
a.set(10);
Product c = a;
c.print();
}실행결과가 예측이 되는가?

복사 생성자를 명시적으로 선언한 결과, c=a가 수행될 때 복사 생성자가 호출되는 것을 볼 수 있고,
c.var에 복사하지 않기 때문에 c.var은 쓰레기값이 나오는 것을 볼 수 있다.
이런 방식으로 C++에서는 연산자 또한 멤버 함수처럼 취급한다는 것을 알 수 있는데, 이는 모든 연산자에 해당이 된다.
그렇기 때문에 연산자 또한 함수처럼 오버로딩이 가능하고, 클래스에 따라 필요한 방식으로 연산자를 오버로딩하여 기존에 쓰던 방식과 유사하게 동작할 수 있도록 설정하는 것이 가능하다.
연산자 오버로딩 방식
연산자를 선언할 때는 operator 키워드를 앞에 붙여준다.
다음 코드를 보자.
#include <iostream>
using namespace std;
class Product {
int var;
public:
Product():var(0) {}
Product(int x) : var(x){}
Product operator+(Product& a) const {
Product b(a.var + var);
return b;
}
void print() const { cout << var << "\n"; }
void set(int x) { var = x; }
};
int main() {
Product a(10);
Product c = a+a;
c.print();
}

Product 타입을 반환하는 operator+에 대해서 오버로딩했다.
기존에 a+a가 컴파일되지 않았던 것에 비해 이번에는 var끼리 잘 더해진 20을 출력해주는 것을 볼 수 있다.
이는 다시 말해서, a+a => a.operator+(a) 로 이해할 수 있다.
물론 전역함수로의 선언도 가능하다.
#include <iostream>
using namespace std;
class Product {
int var;
public:
Product():var(0) {}
Product(int x) : var(x){}
void print() const{ cout << var << "\n"; }
void set(int x) { var = x; }
friend Product operator+(const Product& a, const Product& b);
};
Product operator+(const Product& a, const Product& b) {
return Product(a.var + b.var);
}
int main() {
Product a(10);
Product c = a+a;
c.print();
}이 코드는 위의 코드와 완전히 동일하다.
전역함수로 선언하되 friend 키워드로 멤버 변수에 대한 접근을 허가하여 operator+(a,a) 방식으로 호출한다.
보통 멤버함수와 전역함수가 둘 다 같은 방식으로 오버로딩 되어있다면 멤버함수가 우선시 된다.
하지만 특정 옛날 컴파일러에선 이런 상황에 오류를 발생시킬 수 있으므로 웬만하면 멤버 함수로 오버로딩하는 것이 좋지만, 전역 방식으로 오버로딩 해야 하는 상황이 있으므로 잘 기억해두자.
위의 코드까지 이해했다면, 사실 연산자 오버로딩은 거의 끝났다고 보면 된다.
연산자를 해당 클래스의 함수로 보고 접근하는 방식만 잘 기억하고 뒤로 넘어가자.
오버로딩이 불가능한 연산자
C++ 문법을 혼란시키지 않기 위해서 다음 연산자들은 오버로딩을 불허한다.
| . | 멤버 접근 연산자 |
| .* | 멤버 포인터 연산자 |
| :: | 범위 지정자 |
| ?: | 3항 연산자 |
| sizeof | Byte 크기 계산 연산자 |
| typeid | RTTI 연산자 |
| static_cast | type casting 연산자 |
| dynamic_cast | |
| const_cast | |
| retinterpret_cast |
물론 외울 필요는 없는게, 위의 연산자들은 딱히 오버로딩 할 상황이 없다.
멤버함수로만 오버로딩 가능한 연산자
| = | 대입 연산자 |
| () | 함수 호출 연산자 |
| [] | 배열 접근 연산자 |
| -> | 멤버 접근 포인터 연산자 |
이들은 객체가 존재해야 의미가 있기 때문에 객체의 멤버 함수로만 오버로딩이 가능하다.
연산자를 오버로딩 할 때는 다음과 같은 원칙을 따라야 혼란을 야기하지 않는다.
1. 본래의 기능을 준수한다.
- 같은 연산자인데 객체 별로 다른 결과를 낸다면 코드를 사용할 때 혼돈의 카오스를 맛보게 된다.
2. 연산자의 우선순위는 바뀌지 않는다.
- 우선순위를 바꾸면 그야말로 혼란이기 때문에
3. 매개변수의 디폴트 값 설정은 불가능하다.
4. 연산자의 기본 기능을 오버로딩 할 수는 없다.
- int + int 의 + 연산자를 오버로딩 할 수 없다.
단항 연산자의 오버로딩
기본적으로 동일한 방식으로 진행된다.
하지만 조금 더 생각할 부분이 있다.
접근
int a=10;
++a; 의 경우 어떻게 진행이 될까?
앞선 연산과는 다르게 a를 1 증가시킨 값을 선언하고 그 값을 다시 a에 넣어줄까?
지난 글에서 임시 객체에 대해서 이야기했었다.
값의 전달이나 계산을 위해 임시적으로 메모리에 저장되어지는 객체인데, 임시 객체는 사용할 수록 성능의 저하를 불러온다.
왜냐하면 메모리를 할당하고 초기화 시킨 후 다시 사용하고자 하는 객체에 복사하는 과정을 거쳐야하기 때문이다.
그렇기 때문에 C++에서의 최적화는 이 임시객체를 줄이는 것만으로도 상당한 효과를 불러올 수 있었다.
예시 또한 마찬가지이다.
a.operator++()에 대한 오버로딩을 생각해보자.
int b= a+1; return b; 를 해줄 것인가? 이것이 앞서 말한 임시 객체를 사용하는 방식이다.
임시객체를 사용하지 않으려면 다음과 같이 사용할 수 있다.
#include <iostream>
using namespace std;
class Product {
int var;
public:
Product(int x=0) : var(x){}
void operator++() {
var += 1;
}
void print() const{ cout << var << "\n"; }
void set(int x) { var = x; }
};
int main() {
Product a(10);
//a++;
++a;
a.print();
}

전위 증가 연산자를 operator++() 로 오버로딩한다.
주석으로 처리한 a++; 를 실행해보면, 후위증가에 대한 연산자를 정의하지 않았기 때문에 컴파일 에러가 발생한다.
그리고 a를 출력해보면 10에서 1이 증가한 11이 나오는 것을 볼 수 있다.
후위 증가는 operator++(int) 로 구분한다.
이는 C++의 규칙이므로 깊게 생각하지 않고 사용하면 된다.
위의 a++를 사용가능하도록 하려면 다음의 코드가 필요하다.
#include <iostream>
using namespace std;
class Product {
int var;
public:
Product(int x=0) : var(x){}
void operator++() {
var += 1;
}
void operator++(int) {
var += 1;
}
void print() const{ cout << var << "\n"; }
void set(int x) { var = x; }
};
int main() {
Product a(10);
a++;
++a;
a.print();
}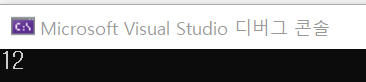
정상적으로 2가 증가한 결과를 볼 수 있다.
그런데 뭔가 이상하지 않은가?
기존에 우리가 사용했던 방식은 cout << a++ << endl; 처럼 연산자 중간에 끼워서 사용할 수 있었다.
하지만 위의 방식은 반환값이 없기 때문에 cout<<에 전달될 인자가 없다.
그렇다면 계속해서 이용할 수 있도록 같은 클래스 타입을 반환해 줄 필요가 느껴진다.
위의 오버로딩을 다음과 같이 바꿔보자.
#include <iostream>
using namespace std;
class Product {
int var;
public:
Product(int x=0) : var(x){}
Product* operator++() {
var += 1;
return this;
}
Product* operator++(int) {
var += 1;
return this;
}
void print() const{ cout << var << "\n"; }
void set(int x) { var = x; }
};
int main() {
Product a(10);
(++a)->operator++();
a.print();
}이제 계산 후 a의 주소값을 반환하기 때문에 포인터 접근을 통해 연속해서 멤버 함수를 이용할 수 있다.
하지만 역시 우리가 사용하던 방식과 다르기 때문에 원래 쓰던 방식대로 사용하기 위해서 참조자를 반환해보자.
#include <iostream>
using namespace std;
class Product {
int var;
public:
Product(int x=0) : var(x){}
Product& operator++() {
var += 1;
return * this;
}
Product& operator++(int) {
var += 1;
return * this;
}
void print() const{ cout << var << "\n"; }
void set(int x) { var = x; }
};
int main() {
Product a(10);
a++++++++++;
a.print();
}
오~~~ 이제 우리가 원래 사용하던대로 사용할 수 있다.
이제 다들 알다시피 포인터 대신 참조값을 반환하여 복사하거나 다른 자잘한 것 없이 원래의 값에 접근해 그대로 사용할 수 있다!
하지만 여전히 의문은 남아있다. a++ 는 같은 레벨의 연산이 모두 끝난 뒤에 a 값을 증가시킬 때 사용하고
++a 는 다른 연산을 수행하기 전에 a 값을 증가시킬 때 사용했었다.
이는 앞서 언급한 바와 같이 임시 객체를 사용함으로써 해결한다.
후위 연산자 a++ 는 임시 객체를 생성하여 반환하고 a 값을 연산에 사용하지 않는다!
고로 위의 코드는 다시 아래와 같이 수정될 수 있다.
#include <iostream>
using namespace std;
class Product {
int var;
public:
Product(int x = 0) : var(x) {}
Product& operator++() {
var += 1;
return *this;
}
Product operator++(int) {
Product tmp(var);
var += 1;
return tmp;
}
void print() const { cout << var << "\n"; }
void set(int x) { var = x; }
};
int main() {
Product a(10);
a++.print();
(++a).print();
}임시객체를 반환하기 때문에 operator++(int) 는 Product 를 반환하는 것으로 변경되었고, 임시 객체를 return 해주는 것으로 바뀌었다. 이제 사용하기만 하면 된다..!
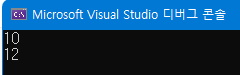
결합법칙
그럼 또다른 문제점을 알아보자.
#include <iostream>
using namespace std;
class Product {
int var;
public:
Product(int x=0) : var(x){}
Product& operator+( int b) {
var += b;
return *this;
}
void print() const{ cout << var << "\n"; }
void set(int x) { var = x; }
};
int main() {
Product a(10);
a + 10;
//10+a;
a.print();
}위의 코드는 문제없이 작동한다.
a 클래스에 대한 오버로딩을 이미 써놨기 때문에 가능하지만, 10+a에 대해서는 불가능하다.
그렇다고 10에 대해서 오버로딩을 하긴 어렵다.
이 때! 전역으로 오버로딩이 필요하다.
아래의 코드를 보자.
#include <iostream>
using namespace std;
class Product {
int var;
public:
Product(int x=0) : var(x){}
Product& operator+( int b) {
var += b;
return *this;
}
void print() const{ cout << var << "\n"; }
void set(int x) { var = x; }
friend Product operator+(int, Product&);
};
Product operator+(int i, Product& p) {
return p + i;
}
int main() {
Product a(10);
a + 10;
10 + a;
a.print();
}10+a의 경우 멤버 함수로 선언할 수 없다.
그렇기 때문에 operator+를 전역으로 오버로딩하여 int 와 Product의 + 연산을 수행할 수 있게 되었다.
물론 이때는 friend 키워드를 붙여서 멤버 변수에 접근할 수 있게 한다.
이것을 보다보면, 연산자 하나 하나 모두 오버로딩을 해야하는가에 대해 회의감이 들기 시작한다...
입출력 연산자
C++ 은 cout 과 << 연산자를 이용해 출력하고, cin과 >> 연산자를 통해 입력받았다.
또한 이 cout 과 cin을 사용하기 위해서 <iostream> 을 포함시켜야 했고, iostream안에 std namespace 에 선언되었기 때문에 std::를 붙여서 접근시켰어야 했다.
cout 은 std 안의 ostream 클래스에 있는 객체이고, cin 은 istream 클래스에 있는 객체이다.
그렇다면 위의 코드에서 Product 클래스의 객체를 cout 과 <<연산자를 통해서 출력하고 싶다면 어떻게 해야할까?
역시 여기서도 오버로딩이 사용된다.
하지만 오버로딩을 시도하기도 전에 문제가 발생한다.
cout << a; 를 생각해보자.
연산자의 사용법을 다시 생각해본다면 위 문장은 다시 cout.operator<<(a); 가 될 것이다.
즉 ostream 클래스에 << 를 오버로딩 해야 Product를 출력할 수 있다는 뜻이다.
하지만 이것은 할 수 없는 일이기 때문에 우리는 전역 함수를 통해 오버로딩해야한다!
전역 함수의 사용법은 반환타입 operator (대상 객체, 입력 객체) 이었으므로 << 연산자에 대해 수행해보자.
#include <iostream>
using namespace std;
class Product {
int var;
public:
Product(int x=0) : var(x){}
Product& operator+( int b) {
var += b;
return *this;
}
void print() const{ cout << var << "\n"; }
void set(int x) { var = x; }
int get() { return var; }
friend ostream& operator<<(ostream&, Product&);
};
ostream& operator<<(ostream& ostrm, Product& p) {
ostrm << p.get();
return ostrm;
}
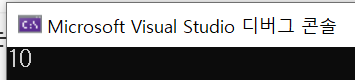
int main() {
Product a(10);
cout << a <<"\n";
}
역시 주의해야할 것은, cout<< a 이후에 연속적으로 << 가 쓰일 수도 있으므로 ostream& 참조자를 return해서 다시 쓸 수 있도록 만들어줘야 한다는 것이다. 또한 friend로 선언했기 때문에 operator<< 를 오버로딩할 때 굳이 p.get()을 통해 가져오지 않아도 되지만 객체 지향 방식으로 작성하고 싶었기 때문에 set과 get method를 이용해 접근하였다.
또한 이미 말했고, 알고 있겠지만, ostream& 클래스로 접근하려면 반드시 iostream이 포함되어 있어야 컴파일 에러가 발생하지 않는다.
마찬가지 방식으로 cin 과 >> 연산자를 오버로딩해보자.
#include <iostream>
using namespace std;
class Product {
int var;
public:
Product(int x=0) : var(x){}
void print() const{ cout << var << "\n"; }
void set(int x) { var = x; }
int get() { return var; }
friend ostream& operator<<(ostream&, Product&);
friend istream& operator>>(istream&, Product&);
};
ostream& operator<<(ostream& ostrm, Product& p) {
ostrm << p.get();
return ostrm;
}
istream& operator>>(istream& istrm, Product& a) {
istrm >> a.var;
return istrm;
}
int main() {
Product a;
cin >> a;
cout << a <<"\n";
}cin은 istream 클래스의 객체이므로 istream 의 >>연산자를 오버로딩해주면 된다.
istream 객체의 별명으로 istrm 을 붙여주고, Product의 별명을 a로 붙여준 후 a.var를 입력받도록 해주면 된다.
물론 연속적으로 사용할 수 있게 return istrm 을 해주어야 한다.
그 후 friend로 설정해주면 끝!
endl은 cout 에 인자로 전달되기도 하고 endl(cout)으로 사용될 수도 있는 녀석이다.
이는 endl 이 단순한 문자가 아니라 함수라는 것을 의미하는데, ostream클래스에 다음과 같이 정의되어 있다.
ostream& endl(ostream &ostrm){
ostrm<<"\n";
fflush(stdout);
return ostrm;
}
class ostream{
public:
void operator<<(ostream& (*fp)(ostream& ostrm)){
return fp(*this);
}cout 이 endl 을 입력받으면 endl 함수를 호출하게 되고, endl함수는 한 줄 띄어주며 fflush 를 사용해 stdout 버퍼를 비워준다. (fflush - C++ Reference (cplusplus.com) 참조)
fflush 를 이용하기 때문에 "\n"을 단순 출력하는 것보다 약간 느리게 동작하기 때문에 알고리즘을 푸는 사람들에겐 비추한다.
이렇게 cin cout 과 endl 에 대해 알아봤고, 어떻게 작동하는지에 대해서도 명확해졌으므로 의심없이 쓰면 되겠다.
그럼 이 글 초입에 설명했던 = 연산자에 대해서 다시 한 번 환기해보자.
=연산자는 컴파일러에 의해 복사 생성자로 변경되어 호출된다.
이 때 얕은 복사에 의해 값들이 그대로 복사되어 대입되는데, 지난 글에서 언급했었다.
2021.05.05 - [C언어] - C++ 프로그래밍 - 클래스의 기초
C++ 프로그래밍 - 클래스의 기초
구조체 vs 클래스 C에서 구조체는 많이 사용해봤을 것이다. 구조체 내의 변수와 함수는 멤버 변수와 멤버 함수라고 명칭한다. C++에서는 구조체 안에 함수를 선언하는 것이 가능해졌으며, .연산자
forswdev.tistory.com
이제 지난 글에서 언급한 복사 생성자의 깊은 복사와 = 연산자를 연결시킬 수 있다.
이외에도 [] 배열 접근 연산자를 오버로딩 할 수도 있는데, 이는 배열에 접근하기(const) + 배열값 바꾸기 + 범위 체크를 하면 되기 때문에 const 함수와 일반 함수를 오버로딩하면 끝나서 굳이 적지 않는다.
new, delete 연산자
이제 아무 의심 없이 사용했던 new와 delete 연산자에 대해서 알아보자.
힙 영역에 객체를 생성하는 과정은 다음과 같이 진행된다고 했었다.
1. 메모리 할당, 2. 생성자 호출을 통한 초기화
그렇다면 생성자와 메모리 할당은 별개라는 뜻인데, 그렇다면 메모리 공간을 할당하는 것이 new연산자인가?
C언어에서는 메모리 할당을 어떻게 했는지 돌이켜보자.
C언어에서는 int * a = (int*) malloc(size); 의 방식으로 할당받았다.
객체의 개념이 없기 때문에 C언어에서는 1.size 만큼의 공간 할당받기, 2. int*로 형변환의 과정을 거쳤다.
C++에선 무엇이 달라졌는가? 객체 개념의 유무이고, 객체는 생성될 때 생성자를 호출했었다.
물론 C++ 에서도 일반적으로 선언하듯이 Product a; 의 선언이 가능했지만, 이는 ()를 생략하여 전달 인자가 없는 상황을 편하게 쓸 수 있도록 해준 것이었다는 것을 생각해보면, new의 역할은 다음 세 가지가 될 것이다.
1. 메모리 공간 할당
2. 생성자 호출
3. 형 변환
이 중 new에 대한 오버로딩은 1번에 대해서만 허용되며, 형식은 void * operator new(size_t size){} 로 제한되어있다.
이것만 보면 malloc 과 동일한 역할을 하는 것을 알 수 있는데, 마찬가지로 Byte단위로 할당된다.
//typedef unsigned int size_t; //로 정의되어 있다.
void * operator new (size_t size){
void * addr = new char[size];
//void * addr = malloc(size);
return addr;
}
int 타입의 공간을 할당 받을 때를 생각해보자.
컴파일러에 의해 size 는 만들고자 하는 객체의 크기(Byte)로 계산되어 자동으로 전달된다.
그렇기 때문에 1Byte 기준으로 배열을 생성하기 때문에 char 배열로 공간을 만들어 준다.
(혹은 malloc 을 사용하여 할당하기도 한다. depend on compiler)
즉, 공간을 할당받을 때 할 수 있는 행동들에 대해 오버로딩이 가능하며, 실제로 malloc 을 이용하여 할당받을 수 있다는 것을 볼 수 있다.
그럼 delete 연산자는 어떤가.
new와 역순으로 생각해보자면
1. 형 변환
2. 소멸자 호출
3. 메모리 공간 해제
가 될 것이다.
물론 소멸자는 더이상 형을 변환시켜서 반환해줄 필요가 없기 때문에 소멸자와 메모리 공간 해제만을 수행해주면 된다.
게다가 new와 마찬가지로 C++에서는 메모리 공간 해제에 대해서만 오버로딩 할 수 있기 때문에 공간 해제만 신경쓰자.
#include <iostream>
using namespace std;
class Product {
int var;
public:
Product(int x = 0):var(x) {
}
friend ostream& operator<<(ostream&, Product&);
static void* operator new(size_t size) {
cout << "NEW\n";
void* addr = new char[size];
return addr;
}
static void operator delete(void* addr) {
cout << "DELETED\n";
delete[] (char *)addr;
}
};
ostream& operator<<(ostream& ostrm, Product& p) {
ostrm << p.var;
return ostrm;
}
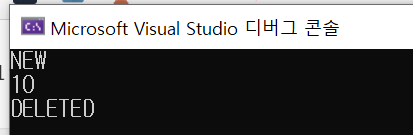
int main() {
Product * a= new Product(10);
cout << *a << "\n";
delete a;
}
이제 알았다!
new 와 delete의 생성자/소멸자 호출과 형변환은 컴파일러가 알아서 해줄테니 우리는 공간을 할당받을 때 어떤 행동을 할 것인가만 고민하면 된다!
또한 delete 연산자는 결국 delete[] 연산을 호출하는 것으로 대신한다는 것도 알 수 있다!
(실제로 delete[] a 도 정상적으로 수행된다)
물론 new[] 연산자와 delete[] 연산자도 오버로딩이 가능하다.
new와 delete 는 객체를 생성하기 전에 사용되는 사용되는 함수이므로 static으로 선언하여 메모리 상에 올려야 멤버 함수 뿐 아니라 정적 함수로 사용할 수 있다.
펑터(Functor) or 함수 오브젝트(Function Object)
객체를 함수처럼 이용할 수 있는 클래스를 펑터 혹은 함수 오브젝트(Function Object)라고 부른다.
함수 호출 연산자는 ()이다.
() 또한 연산자이기 때문에 오버로딩이 가능하며, 클래스 내부에 멤버 함수로 오버로딩할 경우 객체에서 사용할 수 있는 함수가 된다.
()를 펑터로 사용할 경우의 장점이 뭘까?
내가 이해하기로는, 전역함수처럼 이용할 수 있되, 다형성을 구현할 수 있기 때문인 것 같다.
다음 예시를 통해서 살펴보겠다.
#include <iostream>
using namespace std;
class Parent {
public:
virtual void operator()(int a, int b) const= 0;
};
class Child1 : public Parent {
public:
virtual void operator() (int a, int b) const{
cout << "child1 operator : "<< a <<" "<< b << "\n";
}
};
class Child2 : public Parent {
public:
virtual void operator()(int a, int b)const {
cout << "child2 operator : "<< a <<" "<< b << "\n";
}
};
class Printer {
int arr[31];
public:
Printer() {
for (int i = 1; i < 30 / 2; i++) {
arr[2 * i] = 100 + i;
arr[2 * i - 1] = i + 200;
}
}
void printer(const Parent& p) {
for (int i = 1; i < 30 / 2; i++) {
p(arr[2 * i], arr[2 * i - 1]);
}
}
};
int main() {
Printer p;
p.printer(Child1());
endl(cout);
p.printer(Child2());
}
Printer 클래스에 있는 arr[31]을 출력하는 코드를 만들었다.
Printer 클래스에서 void void printer(const Parent &p)를 유심히보자.
p를 마치 함수로 쓰는 것처럼 표현할 수 있다. (p(arr[2*i], arr[2*i-1]);
functor 가 바로 이 개념이다. 객체인 p를 마치 함수처럼 사용할 수 있는 것. 이게 펑터의 끝이다.
함수를 호출하는 것보다 편하게 사용할 수 있어서 STL에 많이 쓰이는 것 같다.
솔직히 그냥 함수를 호출하는 것과 차이를 잘 모르겠지만, 어쨋든 많이 쓰인다고 하니.. 다음 설명을 참고해보자.
Functors in C++ - GeeksforGeeks
Functors in C++ - GeeksforGeeks
A Computer Science portal for geeks. It contains well written, well thought and well explained computer science and programming articles, quizzes and practice/competitive programming/company interview Questions.
www.geeksforgeeks.org
형변환 연산자도 오버로딩이 가능하다.
operator type (){ };
type 에 원하는 형을 넣으면 된다. (int , double...);
형변환 연산자는 반환타입을 명시하지 않는다.
대신 반환값에 따라 형 변환의 결과가 달라진다고 이해하면 된다.
이렇게 연산자 오버로딩까지 공부했다.
여기서 더 다뤄봐야 할 것은 "스마트 포인터"와 "형 변환 연산자" 그리고 타입 마다 하나하나 오버로딩 해야하는 번거로움에 대해서다.
다음 글에서 계속 공부해보겠다.
'C언어' 카테고리의 다른 글
| C++ 프로그래밍 - 예외처리(Exception Handling)와 형변환 연산자(type casting operator) (0) | 2021.05.10 |
|---|---|
| C++ 프로그래밍 - 템플릿(Template) (0) | 2021.05.09 |
| C++ 프로그래밍 - 클래스의 상속(Inheritance)과 다형성(polymorphism) (1) | 2021.05.06 |
| C++ 프로그래밍 - 클래스의 기초 (0) | 2021.05.05 |
| C++ 프로그래밍 - 참조자(Reference) (0) | 2021.05.05 |